Segmentace zákazníků a churn analýza
 O standardních úlohách a projektech v oblasti data science (DS), mezi něž patří i segmentace zákazníků a churn analýza, bylo již napsáno mnoho. Většinou se však jedná o obecné obchodní formulace a málokdo už ví, co všechno se ve skutečnosti skrývá za samotnou realizací takového komplexního DS projektu, jaká je jeho časová náročnost a co všechno musí datový vědec, nebo postaru datový analytik, řešit a s čím se musí popasovat. DS projekty mohou mít mnoho společného, avšak každá realizace je specifická a vyžaduje individuální přístup, aby byly splněny požadavky zadavatele. Pro představu si postup realizace DS projektu představíme na příkladu telekomunikační společnosti (TS). Postupovat budeme v jednotlivých fázích podle metodologie CRISP-DM.
O standardních úlohách a projektech v oblasti data science (DS), mezi něž patří i segmentace zákazníků a churn analýza, bylo již napsáno mnoho. Většinou se však jedná o obecné obchodní formulace a málokdo už ví, co všechno se ve skutečnosti skrývá za samotnou realizací takového komplexního DS projektu, jaká je jeho časová náročnost a co všechno musí datový vědec, nebo postaru datový analytik, řešit a s čím se musí popasovat. DS projekty mohou mít mnoho společného, avšak každá realizace je specifická a vyžaduje individuální přístup, aby byly splněny požadavky zadavatele. Pro představu si postup realizace DS projektu představíme na příkladu telekomunikační společnosti (TS). Postupovat budeme v jednotlivých fázích podle metodologie CRISP-DM.
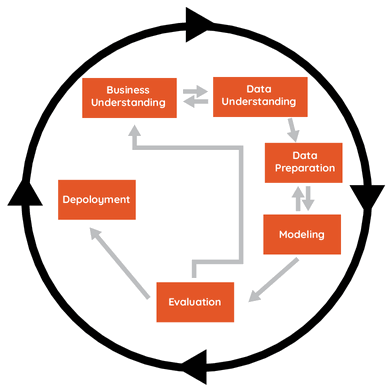
Obr. 1: Schéma metodologie CRISP-DM
1. fáze: Business Understanding
Z osobního setkání se zástupci TS vyplynulo, že mají zájem realizovat personalizované marketingové kampaně zaměřené na skupiny klientů podle jejich využitého objemu dat, provolaných minut a počtu odeslaných textových zpráv za poslední tři měsíce. Pro řešení úlohy tedy bude vytvořen segmentační model, jehož úkolem bude rozdělit klienty do několika skupin podle zvolených charakteristik tak, aby si klienti v jedné skupině byli podobní a naopak z rozdílných skupin byli odlišní vzhledem ke zvoleným charakteristikám. Na každou skupinu pak budou moci být vytvářeny specializované cílené marketingové kampaně (kompetence TS). Požaduje se také najít optimální malý počet skupin a popsat jejich charakteristiku. Zařazování klientů do skupin bude probíhat měsíčně a zároveň se budou sledovat přechody klientů mezi skupinami oproti předchozímu měsíci. Na měsíční bázi se bude také sledovat zastoupení jednotlivých skupin a kvalita segmentačního modelu v čase. Výsledky budou každý měsíc zobrazovány a aktualizovány v přehledném reportu. Notifikace o aktualizaci reportu bude zasílána na vybrané e-mailové adresy.
Dále TS chce realizovat retenční kampaně zaměřené na snížení odchodu klientů ke konkurenci, konkrétně u klientů, u kterých je měsíc do konce smlouvy a je vysoká pravděpodobnost, že během tří měsíců po jejím skončení podají žádost o přenos čísla k jinému operátorovi. Pro tento účel bude vytvořen churn model na základě historických dat o chování klientů. Z něho budeme moci identifikovat a popsat charakteristiky, které zvyšují nebo snižují pravděpodobnost přenosu čísla, a tedy kteří klienti a jejich čísla jsou nejvíce rizikoví. Na rizikové klienty budou pravidelně vytvářeny retenční kampaně a model bude implementován do interního systému (kompetence TS), aby prodejce mohl při komunikaci s klientem vidět jeho rizikovost ve formě barevného semaforu. Na měsíční bázi bude probíhat skórování vytvořeným churn modelem, sledování jeho kvality a míry odchodu klientů (churn rate). Výsledky budou každý měsíc zobrazovány a aktualizovány v přehledném reportu, včetně notifikace o jeho aktualizaci, která bude zasílána na vybrané e-mailové adresy.
Při realizaci projektu se spolupracuje s experty TS. V úvodních dvou fázích pracovníci poskytují podrobné informace o procesech a datech, kterými disponují, včetně způsobu jejich ukládání a popisu. Časová náročnost této fáze je odhadována na 5 MD (člověkodnů).
2. fáze: Data Understanding
TS disponuje množstvím datových zdrojů, které lze využít při budování churn modelu a při výpočtu potřebných charakteristik pro segmentační model. Jedná se o datové zdroje s identifikačními a sociodemografickými údaji o klientech, informace o kontaktech s TS, využívání hlasových, datových, textových a dalších služeb, pohybu na webu a využívání portálu nebo aplikace, podrobný popis celé historie klientů včetně jejich produktů, faktur, upomínek atd.
Seznámili jsme se s daty, jejich strukturou a významem jednotlivých atributů. Zjistili jsme rozsah dat, způsob jejich ukládání, typ proměnných a jejich kódování, číselníky. Provedl se datový audit. Časová náročnost 20 MD.
3. fáze: Data Preparation
Časově nejnáročnější fáze pokrývající všechny činnosti potřebné k vytvoření finální datové matice, která vstupuje do modelování. Vzhledem k potenciálu dalších úloh do budoucna, pravidelnému měsíčnímu skórování, využívání dat v reportech a integraci se vytvořil DS datový sklad, který je pravidelně aktualizován na měsíční bázi. Při tvorbě a aktualizaci datového skladu se z datových zdrojů využívají operace pro výběr, čištění, vytváření (např. výpočtem, agregací nebo restrukturalizací), slučování (vedle sebe nebo pod sebe) a formátování dat. Pro segmentační model slouží datová matice o třech atributech, protože však nejsou měřeny ve stejných jednotkách, a tedy na stejné škále, budou před vstupem do modelu standardizovány.
Pro churn model využíváme datovou matici, která obsahuje atributy odpovídající stavu měsíc před ukončením smlouvy klienta. Atributy pro vstup do modelu zahrnují příznaky produktů klienta, dobu vztahu klienta, provolané minuty do jednotlivých sítí, objem využitých dat, sumu zaplacenou nad rámec paušálu, věk, pohlaví, kraj, rodinný stav, jazyk klienta, příznaky volání z nebo na infolinku konkurence, počet přerušených hovorů, počet stížností atd. Odvozena byla také cílová proměnná, zda během tří měsíců po skončení smlouvy dojde k podání žádosti o přenos čísla k jinému operátorovi. V případě potřeby se realizovala i kategorizace a transformace dat. Před modelováním se datová matice rozdělila na tréninkovou množinu, na které se model vytváří, a testovací množinu, která slouží k vyhodnocení jeho kvality. Časová náročnost 75 MD.
4. fáze: Modeling
Porovnávali jsme různé modelovací algoritmy s různým nastavením parametrů, ale vzhledem k porovnatelné kvalitě a požadavku interpretovatelnosti byla pro churn model zvolena logistická regrese a algoritmus TwoStep pro segmentační model.
Optimálním algoritmem byly stanoveny čtyři klastry. Obrázek níže uvádí průměrné hodnoty atributů pro jednotlivé klastry, které jsou barevně odlišeny pro snadnější interpretaci. V prvním klastru jsou klienti, kteří mají v průměru nízké všechny hodnoty atributů oproti jiným klastrům. Druhý klastr je charakteristický nejvyšším průměrným využitím objemu dat, třetí klastr nejvyššími průměrnými provolanými minutami a čtvrtý klastr nejvyšším průměrným počtem odeslaných textových zpráv.
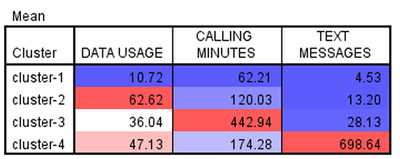
Obr. 2: Průměrné hodnoty v jednotlivých klastrech
Další obrázek představuje odhad regresních koeficientů churn modelu. Z nich je vidět, že nejrizikovější klienti a čísla pro podání žádosti o přenos čísla k jinému operátorovi jsou ti s krátkou dobou čísla u TS, krátkou dobou klienta u TS, klienti s pronájmem jakéhokoliv zařízení, klienti bez čísla s možností dobíjení kreditu, klienti s vysokým počtem provolaných minut, s existencí hlasové schránky, klienti s internetem od TS a s velkým objemem využitých dat. Časová náročnost 5 MD.

Obr. 3: Odhad regresních koeficientů churn modelu
5. fáze: Evaluation
Kvalita segmentačního modelu podle průměrné siluety je vyšší než 0,5. To značí uspokojivý model. Svědčí o tom i rozdíly mezi klastry podle jejich charakteristik. Churn model je podle Giniho evaluační metriky na tréninkové i testovací množině porovnatelný, nedochází k jeho přeučení a je nad hodnotou 0,5, což představuje dobrý model. Postup celého řešení byl před jeho nasazením zkontrolován. Fáze evaluace trvala 2 MD.
6. fáze: Deployment
Řešení je integrováno do rozhodovacích procesů TS. Pro oba modely je nastaveno automatické skórování na měsíční bázi spolu s aktualizací DS datového skladu.
Hlavní výstup segmentačního modelu je databázová tabulka, která obsahuje identifikátor měsíčního snímku, identifikátor klienta, hodnoty vstupních atributů modelu, zařazení do klastru v aktuálním a předchozím snímku. Slouží jako podklad pro cílené marketingové kampaně.
Pro churn model je primárním výstupem databázová tabulka s identifikátorem měsíčního snímku, identifikátorem klienta, telefonním číslem a pravděpodobností podání žádosti o přenos čísla k jinému operátorovi během tří měsíců po skončení smlouvy. Tento výstup slouží jako podklad pro retenční marketingové kampaně a pro integraci rizikovosti klienta do interního systému formou barevného semaforu.
Na závěr byla vytvořena projektová dokumentace a prezentovány dosažené výsledky. Celková náročnost projektu je 120 MD. Někdy je schopen projekt realizovat jeden člověk, ale typicky je to týmová spolupráce kvalifikace a kompetence jednotlivých členů týmu.
 |
Mgr. Ing. Milan Machalec Autor článku je senior data scientist ve společnosti ACREA SR. |









