Nechají se datoví vědci nahradit umělou inteligencí?
 Odborníci v každém oboru si během své kariéry vychovávají své nástupce. Vývoj na poli datové vědy je tak rychlý, že nastupující generace se musí učit technologie, které jejich učitelé dosud nepoužívali. Je vůbec v lidských silách být plnohodnotným datovým vědcem, nebo si musíme vychovat virtuální experty založené na umělé inteligenci? Bude si umělá inteligence v budoucnu schopna vychovávat další generace umělé inteligence?
Odborníci v každém oboru si během své kariéry vychovávají své nástupce. Vývoj na poli datové vědy je tak rychlý, že nastupující generace se musí učit technologie, které jejich učitelé dosud nepoužívali. Je vůbec v lidských silách být plnohodnotným datovým vědcem, nebo si musíme vychovat virtuální experty založené na umělé inteligenci? Bude si umělá inteligence v budoucnu schopna vychovávat další generace umělé inteligence?
Datová věda a umělá inteligence představovaná strojově učenými modely k sobě neodmyslitelně patří. Díky potřebě řešit úlohy, na které naše vlastní inteligence nestačí, jsme si vytvořili algoritmy produkující predikční postupy. Algoritmy při strojovém učení hledají v předložených datech pravidla umožňující předpovídat budoucí události. A pokud se nám podaří v datech užitečná pravidla najít a postavit z nich model, jehož předpovědi dokážeme využívat, máme umělou inteligenci. Ta umí sice jen to, co jsme jí zadali, aby se naučila, ale rozhoduje se velmi rychle, je objektivní, nezapomíná a optimálně využívá informace nalezené v tréninkových datech.
Strojové učení a umělá inteligence
Strojově naučené modely jsou automaticky sestavené programy transformující vstupní data na data výstupní. Může se jednat o jednoduchý i složitý algoritmus popsaný parametry, jejichž hodnoty se odhadly během strojového učení tak, aby předpovědi byly co nejpřesnější. Například regresní model v sobě ukrývá regresní koeficienty nebo neuronový model je vybaven množstvím synaptických vah.
Strojově naučené modely můžeme snadno kopírovat či modifikovat. Také je můžeme kombinovat, využívat jen část predikčního modelu a vytvářet hybridní víceúčelové ansámbly a hluboké sítě, které dokáží řešit mnoho úloh. A pokud vhodně nakombinujeme komponenty složeného modelu tak, že bude schopen doučovat se nové úlohy na nových datech, získáme velmi výkonnou umělou inteligenci.
Například základem umělé inteligence vedoucí s námi dialog je model pro predikci slov na základě kontextu. Z hlediska datové vědy se jedná o nominální klasifikátor. Díky široké slovní zásobě přirozených jazyků je žádoucí sestavit značně rozsáhlý klasifikátor, který bude navíc ještě schopen zohlednit morfologická a syntaktická pravidla. Modelu však můžeme ve fázi strojového učení nabídnout ohromné množství textu, jehož postupným procházením vznikne velmi mnoho učebních instancí zahrnujících predikované slovo a jeho kontext představovaný sousedními slovy. V angličtině se takové učení nazývá self supervised learning.
Algoritmus pro predikci slov na základě kontextu se v počítačovém zpracování přirozených jazyků označuje jako jazykový model. Dříve se používaly pravděpodobnostní modely, dnes je nahradily hluboké neuronové sítě s velkým množstvím synaptických vah, proto se jim říká velké jazykové modely. Naučit velký jazykový model predikovat slova na základě kontextu není jednoduché, ale pokud ho již máme, můžeme z něj vyžívat jeho části, doplňovat ho dalšími moduly a doučovat ho. Tak vzniká umělá inteligence, jakou dnes využíváme k sumarizaci textů, strojovým překladům, psaní programového kódu nebo vedení dialogu.
Stále se však jedná o strojově naučené modely transformující vstupní data na výstupní. Díky skládání mnoha modelů do vrstev se v nich data transformují mnohokrát. Proto se také komplexním modelům tvořícím základ umělé inteligence anglicky říká transformers. Většina transformací datových vektorů je pro nás skrytá, a tak se nám jeví, že umělá inteligence dokáže řešit komplexní a těžké úlohy. Dnešní velké jazykové modely se skládají z mnoha modulů, které texty zakódují a pak je zase rozkódují do nového datového vektoru, a to ještě takovým způsobem, že transformace není fixní, ale závisí na kontextu. Podle kontextu je některým slovům či jejich významům v rámci věty přikládána při transformaci větší či menší důležitost. Díky takovým transformacím se původní řídká datová reprezentace slov, vět, odstavců a dokumentů přemění do struktury, kterou mohou využívat připojené jednodušší predikční modely.
Analytický a syntetický model
Na klasické predikční modely používané v datové vědě, jakými jsou například klasifikátory, můžeme nahlížet jako na modely analytické. V rozsáhlých datech hledají při strojovém učení opakující se vzory vysvětlující studovaný jev. Například při učení modelu na schvalování žádosti o úvěr hledáme v historických datech příčiny selhání schválených úvěrů. Naučený model nalezené vzory chování využívá a rozsáhlejší vstupní data transformuje na primitivní predikce. Dochází přitom k extrakci užitečné informace a vstupní data se redukují na srozumitelná doporučení.

Umělá inteligence ale naopak poskytuje komplexní výstupy na základě často jednoduchého zadání. Umí nakreslit obraz, složit hudbu nebo napsat článek. Výstupy umělé inteligence jsou syntetické, protože AI modely jsou tvořeny mnoha dílčími analytickými modely a dokáží jejich výstupy vhodně kombinovat. Hluboké neuronové sítě se skládají z vrstev a modulů, každý modul má svoji roli. Některé analyzují zadání, jiné připravují a transformují data a nejvyšší vrstvy syntetizují obraz, zvuk nebo text.
Umělá inteligence v datové vědě
Nabízí se tedy otázka, zda současná umělá inteligence umí nahradit práci datových vědců. Jedná se především o sestavování analytických predikčních modelů na základě dat o pacientech, zákaznících, výrobcích, pojistných událostech apod. Ale nejen to. Datový vědec jedná s uživateli, čerpá a transformuje data z databází, programuje a zavádí řešení do provozu.

Obr. 1: Konverzace s ChatGPT o řešení projektu na vytvoření aplikační skórovací karty.
Pokud se budete snažit umělé inteligenci předat učební data nebo se jí jen zeptáte, zda by na základě historických dat mohla sestavit například skórovací kartu na schvalování úvěrů, zjistíte, že s rozsáhlejšími tabulkovými daty pracovat neumí. Datoví vědci se tak stále musí spoléhat na svou vlastní inteligenci a vytvářet analytické predikční modely sami. Ačkoli AI problém za datové vědce nevyřeší, přesto může pro ně být dobrým pomocníkem a datový vědec může na umělou inteligenci delegovat některé dílčí rutinní úkoly a sám se s nadhledem věnovat řízení projektu.
V datové vědě se při řešení úloh již mnoho let postupuje podle metodologie CRISP-DM. Díky hierarchickému dělení projektu na jednodušší etapy snadno zjistíme, že predikční modelování, kde práci za nás AI neudělá, je jen jednou z šesti fází. Zbylé fáze zahrnují definování úlohy a plánování projektu, analýzu dostupných dat, přípravu a čistění datové matice, měření přínosů modelu a implementaci navrženého řešení do provozu. V mnohých z těchto fází můžeme AI angažovat. Umělá inteligence může být taktéž průvodcem pro začínající datové vědce a konzultovat s nimi další postup v projektu.
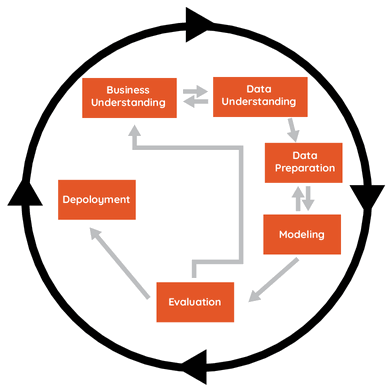
Obr. 2: Lety prověřená metodologie CRISP-DM rozděluje dataminingový projekt na šest různých fází. Umělá inteligence může datové vědce při řešení navigovat a v každé fázi pomoci odlišným způsobem.
Umělá inteligence nepochybně najde své místo na začátku a konci každého projektu. Může zastoupit konzultanta při jednání se zákazníkem, kdy je třeba definovat úlohu z obchodního hlediska a převézt ji na úlohu analytickou. Na konci projektu zase může AI navrhnout grafické rozhraní pro vznikající mobilní aplikaci nebo doporučit postup zpracování úvěrové žádosti.
I v průběhu řešení projektu může být umělá inteligence prospěšná. Umí totiž generovat programový kód. Při přípravě dat ji lze úspěšně požádat o sestavení SQL skriptu, při modelování a evaluaci nám doporučí vhodné knihovny, objekty a metody v Pythonu. I když nebude kód napsaný tak, že ho můžeme rovnou spustit, jeho přizpůsobení na dostupná data bude jistě jednodušší než vymýšlení nového kódu.
Pokud se rozhodnete umělou inteligenci v datové vědě využívat alespoň pro dílčí kroky, nezapomeňte ji kontrolovat. Kdyby úlohu řešil datový vědec bez podpory AI na pozadí metodologie CRISP-DM, také by své kroky konzultoval s kolegy a budoucími uživateli. Umělá inteligence se od nás naučila dělat chyby, i když se jich nedopouští tak často.
Zkuste si popovídat o konkrétní úloze s některým běžně používaným chatbotem. Zjistíte, že podobně jako v reálném projektu se vynoří mnoho otázek, po jejichž zodpovězení dokážeme specifikovat úlohu, naplánovat projekt a hlavně si vytvoříme potřebnou vizi, jak bude vypadat nasazení hotového řešení do provozu. S chatbotem můžete řešit podobu konkrétního programového kódu, způsob spojování a čištění dat, výběr predikčního algoritmu či způsob měření kvality modelu. Jediné, s čím nám nepomůže, je vlastní zpracování dat a vytvoření modelu. Tedy alespoň zatím.
AI nástroje pro datové vědce
Již dnes však vznikají aplikace, které vás provedou projektem tak, jako byste postupovali podle tištěného průvodce metodologií CRISP-DM. Tím průvodcem je však umělá inteligence. Aplikace narozdíl od čistého chatbota umí navíc převzít data, provést v nich některé změny a naučit predikční model. Ten se třeba uloží na serveru a obalí se vhodným API, aby mohl být volán koncovými uživateli.

Obr. 3: Dialog s umělou inteligencí v softwaru Pecan. Na základě úvodní konverzace si software vyžádá data, připraví analytické prostředí a nabídne nástroje na sestavení a provoz modelu.
Těmto vznikajícím aplikacím se dá ještě mnohé vytknout, ale domnívám se, že se jedná o krok správným směrem. Na rozdíl od dnes masivního používání Pythonu a jeho knihoven nabídnou datovému vědci tolik potřebný nadhled nad celým projektem podobně, jako to nabízely a nabízejí komplexní dataminigové softwary. Při nasazení umělé inteligence datový vědec navíc získá průvodce, kolegu a možná i učitele. Tento virtuální asistent pomáhá datovému vědci především při řešení technických dílčích kroků, které ho zbytečně rozptylují.
 |
Mgr. Ondřej Háva, Ph.D. Autor je senior analytik a lektor data miningu v ACREA CR. Ve své profesní kariéře se specializuje na dataminingové projekty, a to především v oblasti řízení rizik a detekce podvodů. Má zkušenost s vedením rozsáhlých dataminingových projektů. |









